O que é Hadoop? Kaptár

Ao usar o EMR File System (EMRFS) no cluster do Amazon EMR, é possível utilizar o Amazon S3 como a layer de dados do Hadoop. O Amazon S3 é altamente escalável, de baixo custo e projetado para durabilidade, o que o torna um datastore excelente para o processamento de big data. Ao armazenar dados no Amazon S3, você pode desassociar a layer de computação da layer de armazenamento, o que.
Hadoop 101 一步一步
Descubra o Hadoop e seus componentes mais populares, os desafios, benefícios, como é usado e um pouco da história dessa estrutura open-source.. Sandbox para descobertas e análises. Uma vez que o Hadoop foi projetado para lidar com volumes de dados em uma variedade de formas e tamanhos, ele pode executar algoritmos analíticos.
Hadoop pros y contras Barcelona Geeks
O papel do Hadoop na IoT (Internet das Coisas) Uma das soluções que o Hadoop oferece é o armazenamento e as condições para processar quantidades inimagináveis de dados. O Big Data não para de crescer. Há cinco anos, gerávamos pouco mais da metade dos dados que geramos hoje. Há 15 anos, a quantidade de dados que produzíamos em 24.
Entenda o que é a Hadoop e como funciona!

Introdução. O Apache Hadoop é uma plataforma de software de código aberto baseada em Java que gerencia o processamento e o armazenamento de dados para aplicações de big data. A plataforma funciona distribuindo jobs de big data e análise do Hadoop entre nós em um cluster de compute, dividindo-os em workloads menores que podem ser.
Apache Hadoop É hoje que vai instalar o seu primeiro cluster?
Você não precisa ser técnico para saber que os Dados e #BigData são importantes e que estão transformando muito negócios. Mas sempre que lê algo sobre #BigDa.
Apache Hadoop Tudo o que você precisa saber Artigo Cetax

🔥Post Graduate Program In Data Engineering: https://www.simplilearn.com/pgp-data-engineering-certification-training-course?utm_campaign=BigData-aReuLtY0YMI-.
O Hadoop é um software que usa uma rede de muitos computadores para processar grande quantidade

Hadoop ecosystems help with the processing of data and model training operations for machine learning applications. Start building on Google Cloud with $300 in free credits and 20+ always free products. Hadoop, an open source framework, helps to process and store large amounts of data. Hadoop is designed to scale computation using simple modules.
Big Data O que é o hadoop, map reduce, hdfs e hive
Apache Hadoop (/ h ə ˈ d uː p /) is a collection of open-source software utilities that facilitates using a network of many computers to solve problems involving massive amounts of data and computation. [vague] It provides a software framework for distributed storage and processing of big data using the MapReduce programming model.Hadoop was originally designed for computer clusters built.
O que é Hadoop? (Parte 1) YouTube

What is Hadoop? Hadoop is an open-source, trustworthy software framework that allows you to efficiently process mass quantities of information or data in a scalable fashion. As a platform, Hadoop promotes fast processing and complete management of data storage tailored for big data solutions.
Calaméo Qué Significa Hadoop En El Mundo Del

Hadoop é uma estrutura de software open-source para armazenar dados e executar aplicações em clusters de hardwares comuns. Ele fornece armazenamento massivo para qualquer tipo de dado, grande.
Cluster Hadoop aprenda a configurar Blog 4Linux

O que é o Hadoop e porque é importante? Hadoop é um framework de software de código aberto para armazenar dados e executar aplicações em clusters de hardware de commodity. Ele fornece armazenamento massivo para qualquer tipo de dados, enorme poder de processamento e a capacidade de lidar com tarefas ou trabalhos simultâneos praticamente ilimitados. […]
Apache Hadoop O que é e como usálo?

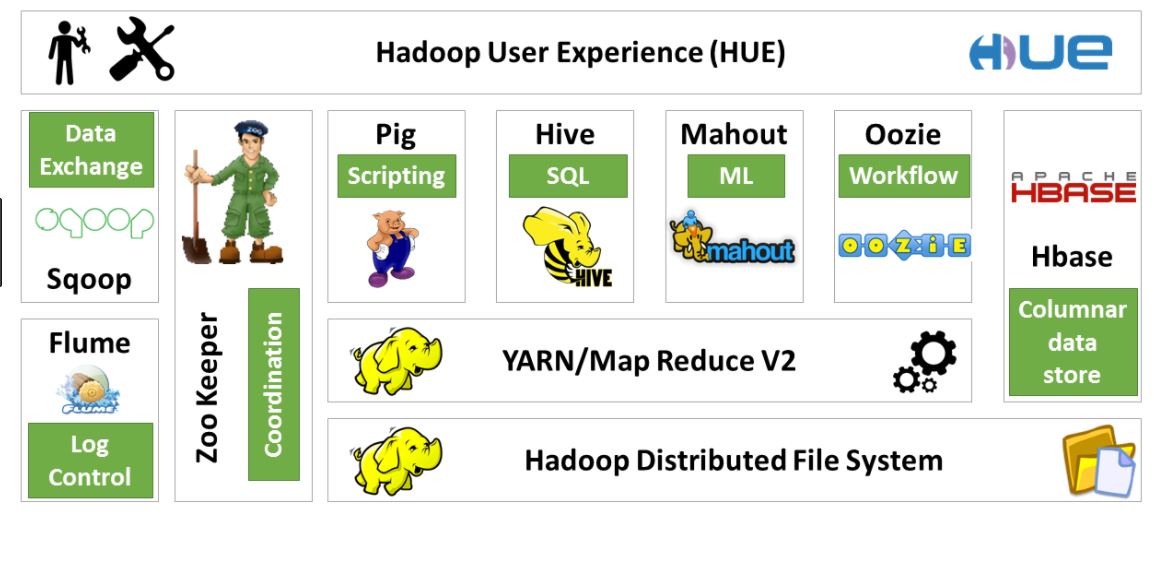
O ecossistema Apache Hadoop se refere aos vários componentes da biblioteca de software Apache Hadoop. Ele inclui projetos de código aberto, bem como todas as ferramentas complementares. Algumas das ferramentas mais conhecidas no ecossistema Hadoop incluem HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase Oozie, Sqoop, Zookeeper e muito mais.
Qué es Hadoop? Introducción e Instalación Mauricio Anderson

Tutorial de teste de Big Data: o que é, estratégia, como testar o Hadoop; As 60 principais perguntas e respostas da entrevista do Hadoop (2024) 13 ferramentas e software de análise de Big Data (atualização de 2024) As 15 principais ferramentas e software de Big Data (código aberto) 2024; Tutorial Talend - O que é a ferramenta Talend ETL?
Big Data O que é o hadoop, map reduce, hdfs e hive
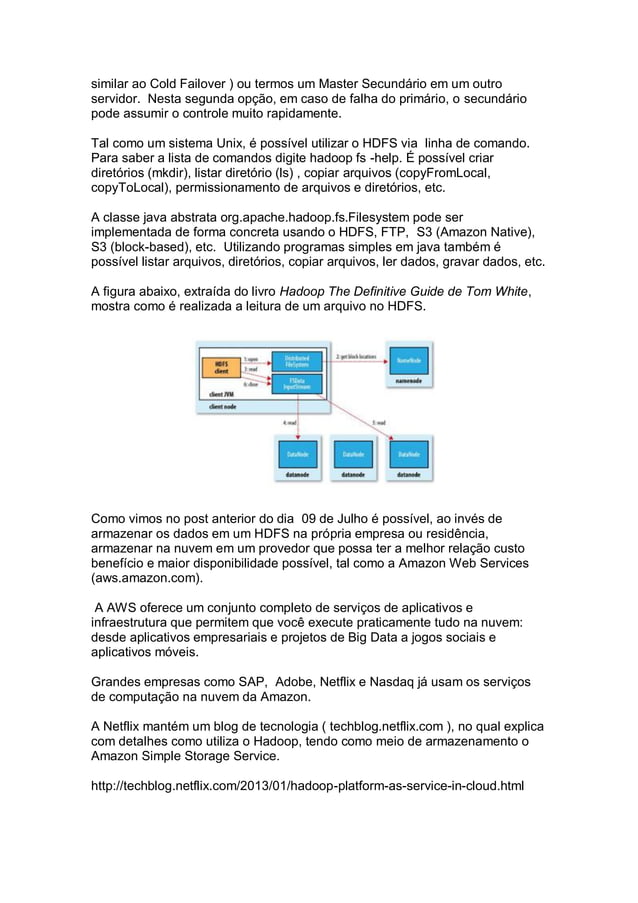
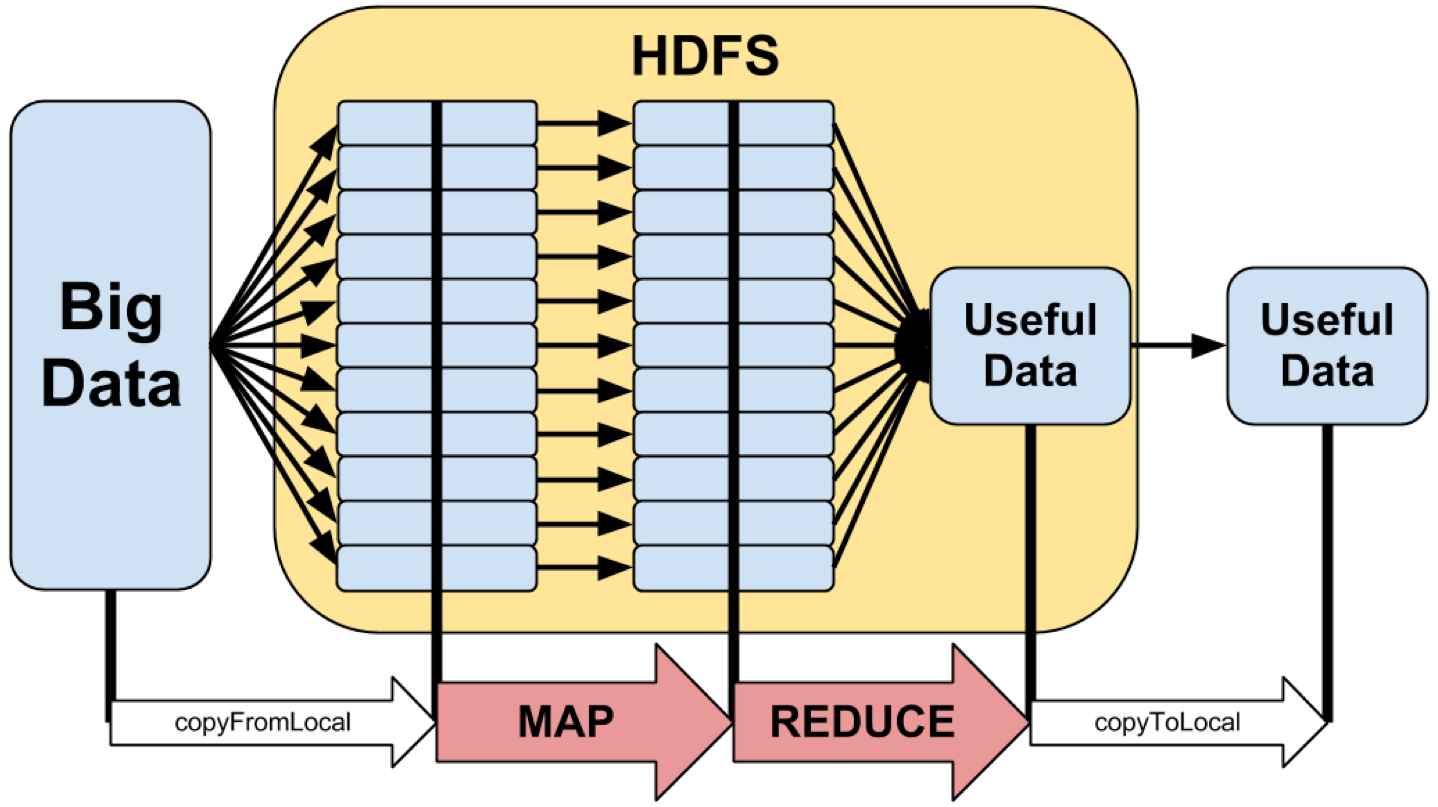
O Hadoop é uma implementação de código aberto, mantida pela Apache, do paradigma de programação Map-Reduce. Esse, foi introduzido pelo Google para processar e analisar grandes quantidades de dados. Tal paradigma define uma arquitetura para a realização do processamento de conjuntos de dados em paralelo. De modo que possam ser executados.
Entenda como o Hadoop pode deixar sua infraestrutura mais eficiente

O Amazon EMR é um serviço gerenciado que permite processar e analisar conjuntos de dados grandes usando as versões mais recentes de frameworks de processamento de big data, como Apache Hadoop, Spark, HBase e Presto, em clusters totalmente personalizáveis.. Fácil de usar: você pode executar um cluster do Amazon EMR em poucos minutos. Você não precisa se preocupar com o provisionamento.
O que é Hadoop? De maneira simples e objetiva YouTube

Segundo a IBM, 90% dos dados no mundo hoje, foram produzidos nos últimos dois anos. São dados originados por smartphones, redes sociais, plataformas de comér.